There are several types of cross validation, but they are all aimed at helping us prevent a specific type of data leakage, using training data in some way when testing your model, in other words giving your model access to information it wouldn’t already have. Let’s talk about why this is important, and some common mistakes when performing cross validation.
This isn’t the only type of data leakage, data leakage is simple any situation where a model gets access to information it otherwise wouldn’t know. For instance you might have data leakage because your model includes a particular feature that it wouldn’t otherwise ‘see.’
What is great about cross validation is that it allows us to make ‘more use’ of our data to do things like tune parameters or feature selection without risking data leakage. We do this by splitting our data up into training and validation sets in some way. We then train our model on the training set and validate it on the validation set, this allows us to test different models (models with different tuning parameters are considered different models) without using our test set, which should only be used after we have finalized our model.
For instance, in k-fold cross validation we break our dataset up into k parts. At each fold we choose one part to be the validation set and the other k-1 parts to be the training set, then we train our model on the training set and validate it on the validation set. At the end we can plot or average some performance measure (accuracy, error, AUC score, etc) over all of the k folds.
Below is a visualization of the splits that occur in 5-fold cross validation.
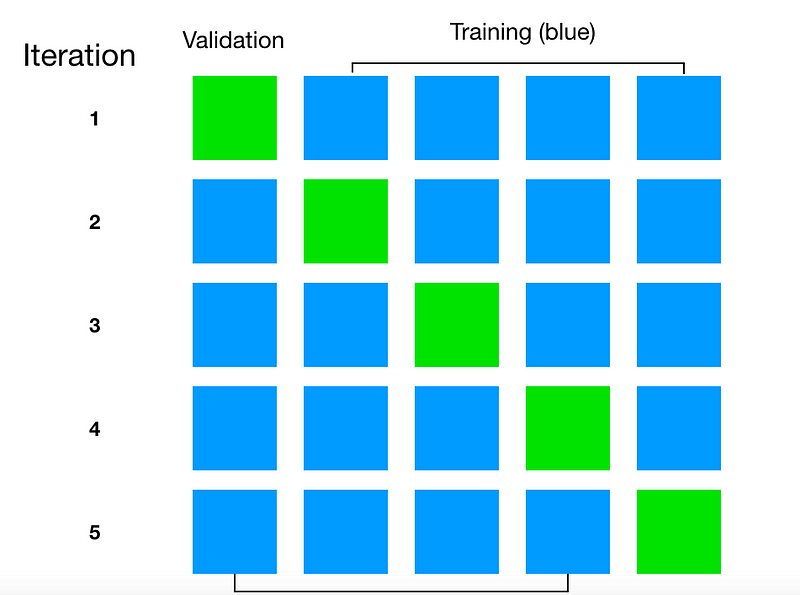
Sounds good, but once you actually start to build your model it is possible to overlook causes of data leakage even while using cross validation.
Using cross validation to compare the performance of different model types is a common practice. The reason for this is that models are sensitive to the data that they are trained on. By averaging a performance metric over many folds we can get some sense of which model will, on average, best generalize to new data. But what if we also need to tune parameters or perform feature selection?
It might be tempting to look at a correlation matrix, or model’s feature importance to select features before cross validation or just tune the parameters in the same fold you are using for model selection. The only problem is, now you have introduced data leakage! You’ve essentially used the same data to tune the parameters and evaluate model performance. You’ve overfit your data, causing you to overestimate your model’s performance.
This is why you should be using nested cross validation. Otherwise you will be using the same data to tune the parameters and evaluate model performance. You will overfit your data, causing you to overestimate your model’s performance.
You should also be looping over your cross validation to understand your models’ sensitivity. The number of times depends on the size of your data set, computational capabilities (this is computationally expensive) etc.
In the following diagram we depict a basic process flow. First we do a standard train test split, then we perform a nested CV (or bootstrap, etc) as shown.
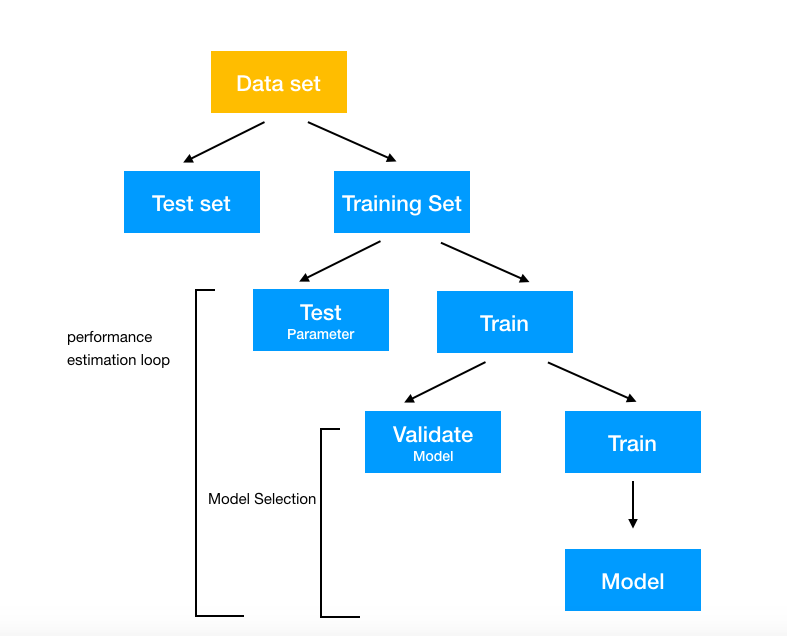
This takes more work, but it helps give us confidence when we finally choose our final model, knowing there is a better chance it will generalize well.
Friedman, Jerome H, et al. “Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2nd Edition.” The United States War on Drugs, Springer-Verlag, 2001, web.stanford.edu/~hastie/ElemStatLearn/.
Nested versus non-nested cross-validation, http://scikitlearn.org/stable/auto_examples/model_selection/plot_nested_cross_validation_iris.html